
This article was originally published by Ben Dickson on TechTalks, (March 7, 2022) a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech, and what we need to look out for. You can read the original article here.
Among the known limits of deep learning is need for massive training data and lack of robustness in dealing with novel situations. The latter is referred to as “out-of-distribution generalization” or sensitivity to “edge cases.”
Those are problems that humans and animals learn to solve very early in their lives. You don’t need to drive off a cliff to know that your car will fall and crash. You know that when an object occludes another object, the latter still exists even if can’t be seen. You know that if you hit a ball with a club, you will send it flying in the direction of the swing.
We learn most of these things without being explicitly instructed, purely by observation and acting in the world. We develop a “world model” during the first few months of our lives and learn about gravity, dimensions, physical properties, causality, and more. This model helps us develop common sense and make reliable predictions of what will happen in the world around us. We then use these basic building blocks to accumulate more complex knowledge.
Current AI systems are missing this commonsense knowledge, which is why they are data hungry, required labeled examples, and are very rigid and sensible to out-of-distribution data.
The question LeCun is exploring is, how do we get machines to learn world models mostly by observation and accumulate the enormous knowledge that babies accumulate just by observation?
Self-supervised learning
LeCun believes that deep learning and artificial neural networks will play a big role in the future of AI. More specifically, he advocates for self-supervised learning, a branch of ML that reduces the need for human input and guidance in training of neural networks.
The more popular branch of ML is supervised learning, in which models are trained on labeled examples. While supervised learning has been very successful at various applications, its requirement for annotation by an outside actor (mostly humans) has proven to be a bottleneck. First, supervised ML models require enormous human effort to label training examples. And second, supervised ML models can’t improve themselves because they need outside help to annotate new training examples.
In contrast, self-supervised ML models learn by observing the world, discerning patterns, making predictions (and sometimes acting and making interventions), and updating their knowledge based on how their predictions match the outcomes they see in the world. It is like a supervised learning system that does its own data annotation.
The self-supervised learning paradigm is much more attuned to the way humans and animals learn. We humans do a lot of supervised learning, but we earn most of our fundamental and commonsense skills through self-supervised learning.
Self-supervised learning is an enormously sought-after goal in the ML community because a very small fraction of the data that exists is annotated. Being able to train ML models on huge stores of unlabeled data has many applications.
In recent years, self-supervised learning has found its way into several areas of ML, including large language models. Basically, a self-supervised language model is trained by being provided with excerpts of text in which some words have been removed. The model must try to predict the missing parts. Since the original text contains the missing parts, this process requires no manual labelling and can scale to very large corpora of text such as Wikipedia and news websites. The trained model will learn solid representations of how text is structured. It can be used for tasks such as text generation or fine-tuned on downstream tasks such as question answering.
Scientists have also managed to apply self-supervised learning to computer vision tasks such as medical imaging. In this case, the technique is called “contrastive learning,” in which a neural network is trained to create latent representations of unlabeled images. For example, during training, the model is provided with different copies of an image with different modifications (e.g., rotation, crops, zoom, color modifications, different angles of the same object). The network adjusts its parameters until its output remains consistent across different variations of the same image. The model can then be fine-tuned on a downstream task with fewer labeled images.

More recently, scientists have experimented with pure self-supervised learning on computer vision tasks. In this case, the model must predict the occluded parts of an image or the next frame in a video.
This is an extremely difficult problem, LeCun says. Images are very high-dimensional spaces. There are near-infinite ways in which pixels can be arranged in an image. Humans and animals are good at anticipating what happens in the world around them, but they do not need to predict the world at the pixel level. We use high-level abstractions and background knowledge to intuitively filter the solution space and home in on a few plausible outcomes.

For example, when you see a video of a flying ball, you expect it to stay on its trajectory in the next frames. If there’s a wall in front of it, you expect it to bounce back. You know this because you have knowledge of intuitive physics and you know how rigid and soft bodies work.
Similarly, when a person is talking to you, you expect their facial features to change across frames. Their mouth, eyes, and eyebrows will move as they speak, they might slightly tilt or nod their head. But you don’t expect their mouth and ears to suddenly switch places. This is because you have high-level representations of faces in your mind and know the constraints that govern the human body.
LeCun believes that self-supervised learning with these types of high-level abstractions will be key to developing the kind of robust world models required for human-level AI. One of the important elements of the solution LeCun is working on is Joint Embedding Predictive Architecture (JEPA). JEPA models learn high-level representations that capture the dependencies between two data points, such as two segments of video that follow each other. JEPA replaces contrastive learning with “regularized” techniques that can extract high-level latent features from the input and discard irrelevant information. This makes it possible for the model to make inferences on high-dimensional information such as visual data.
Modular architecture
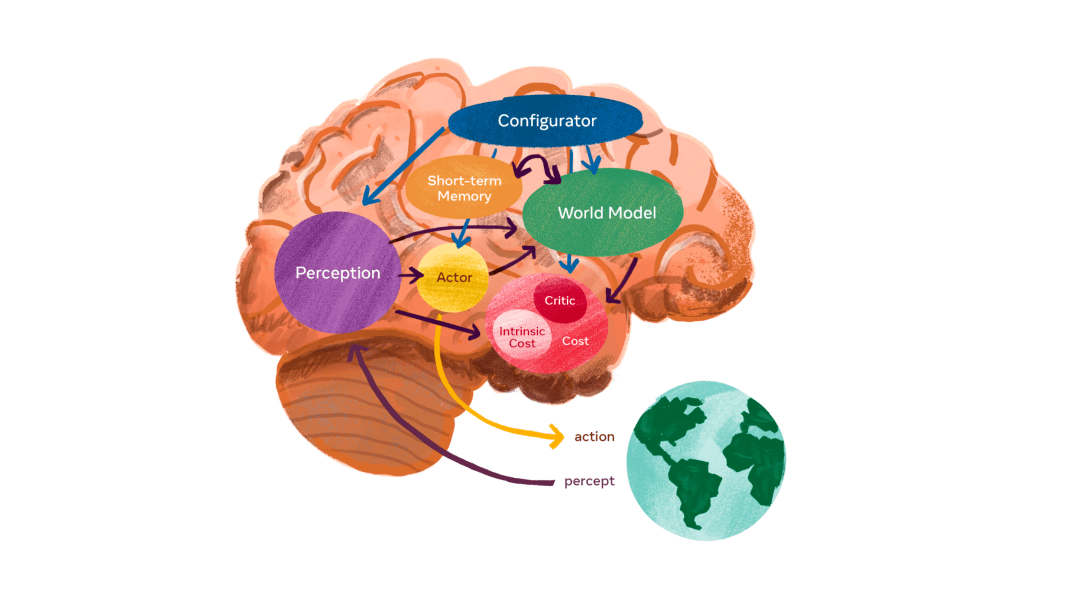
At the Meta AI event, LeCun also talked about a modular architecture for human-level AI. The world model will be a key component of this architecture. But it will also need to coordinate with other modules. Among them is a perception module that receives and processes sensory information from the world. An actor module turns perceptions and predictions into actions. A short-term memory module keeps track of actions and perceptions and fills the gaps in the model’s information. A cost module helps evaluate the intrinsic—or hardwired—costs of actions as well as the task-specific value of future states.
And there’s a configurator module that adjusts all other modules based on the specific tasks that the AI system wants to perform. The configurator is extremely important because it regulates the limited attention and computation resources of the model on the information that is relevant to its current tasks and goals. For example, if you’re playing or watching a game of basketball, your perception system will be focused on specific features and components of the world (e.g., the ball, players, court limits, etc.). Accordingly, your world model will try to predict hierarchical features that are more relevant to the task at hand (e.g., where will the ball land, to whom will the ball be passed, will the player who holds the ball shoot or dribble?) and discard irrelevant features (e.g., actions of spectators, the movements and sounds of objects outside the basketball court).
LeCun believes that each one of these modules can learn their tasks in a differentiable way and communicate with each other through high-level abstractions. This is roughly similar to the brain of humans and animals, which have a modular architecture (different cortical areas, hypothalamus, basal ganglia, amygdala, brain stem, hippocampus, etc.), each of which have connections with others and their own neural structure, which gradually becomes updated with the organism’s experience.
What will human-level AI do?
Most discussions of human-level AI are about machines that replace natural intelligence and perform every task that a human can. Naturally, these discussions lead to topics such as technological unemployment, singularity, runaway intelligence, and robot invasions. Scientists are widely divided on the outlook of artificial general intelligence. Will there be such a thing as artificial intelligence without the need to survive and reproduce, the main drive behind the evolution of natural intelligence? Is consciousness a prerequisite for AGI? Will AGI have its own goals and desires? Can we create a brain in a vat and without a physical shell? Those are some of the philosophical questions that have yet to be answered as scientists slowly make progress toward the long-sought goal of thinking machines.
But a more practical direction of research is creating AI that is “compatible with human intelligence.” This, I think, is the promise that LeCun’s area of research holds. This is the kind of AI that might not be able to independently make the next great invention or write a compelling novel, but it will surely help humans become more creative and productive and find solutions to complicated problems. It will probably make our roads safer, our healthcare systems more efficient, our weather prediction technology more stable, our search results more relevant, our robots less dumb, and our virtual assistants more useful.
In fact, when asked about the most exciting aspects of the future of human-level AI, LeCun said he believed it was “the amplification of human intelligence, the fact that every human could do more stuff, be more productive, more creative, spend more time on fulfilling activities, which is the history of technological evolution.”
