
Barcelona, January 4, 2022.- The following analysis on Deep Learning and the use of neural networks has been published by the IEEE Spectrum magazine. Technologies already present in smartphones and that will evolve faster, every day.
TODAY’S BOOM IN AI is centered around a technique called deep learning, which is powered by artificial neural networks. Here’s a graphical explanation of how these neural networks are structured and trained.
ARCHITECTURE
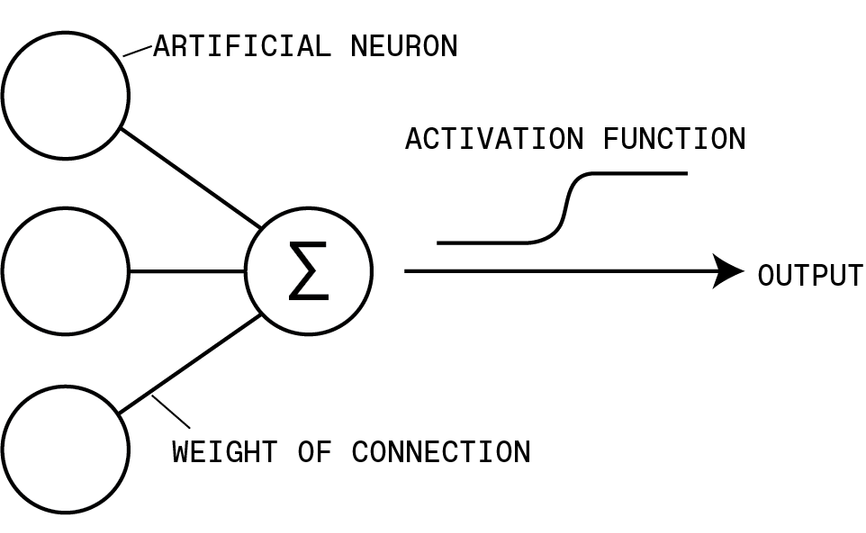
Each neuron in an artificial neural network sums its inputs and applies an activation function to determine its output. This architecture was inspired by what goes on in the brain, where neurons transmit signals between one another via synapses.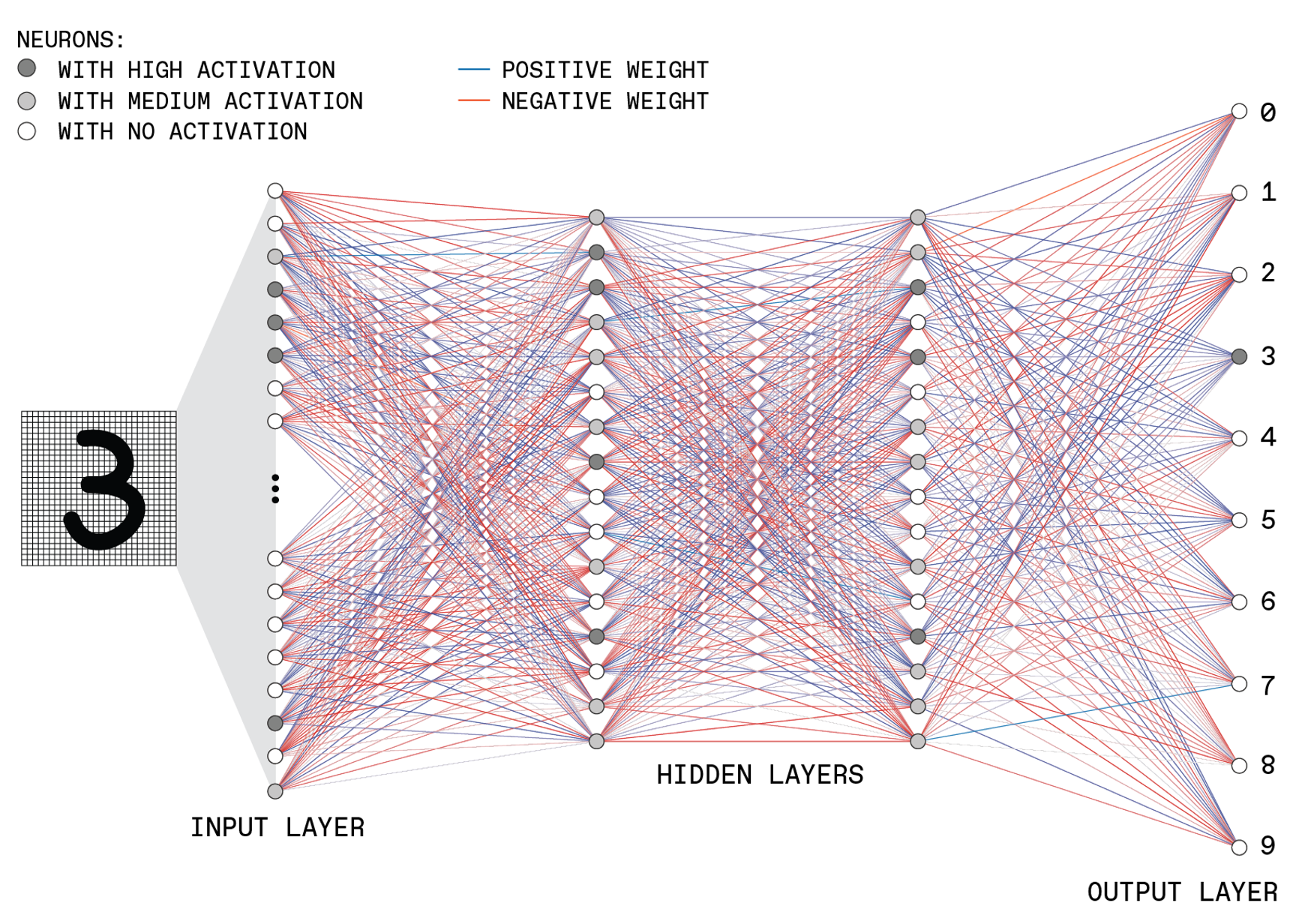 DAVID SCHNEIDER
DAVID SCHNEIDER
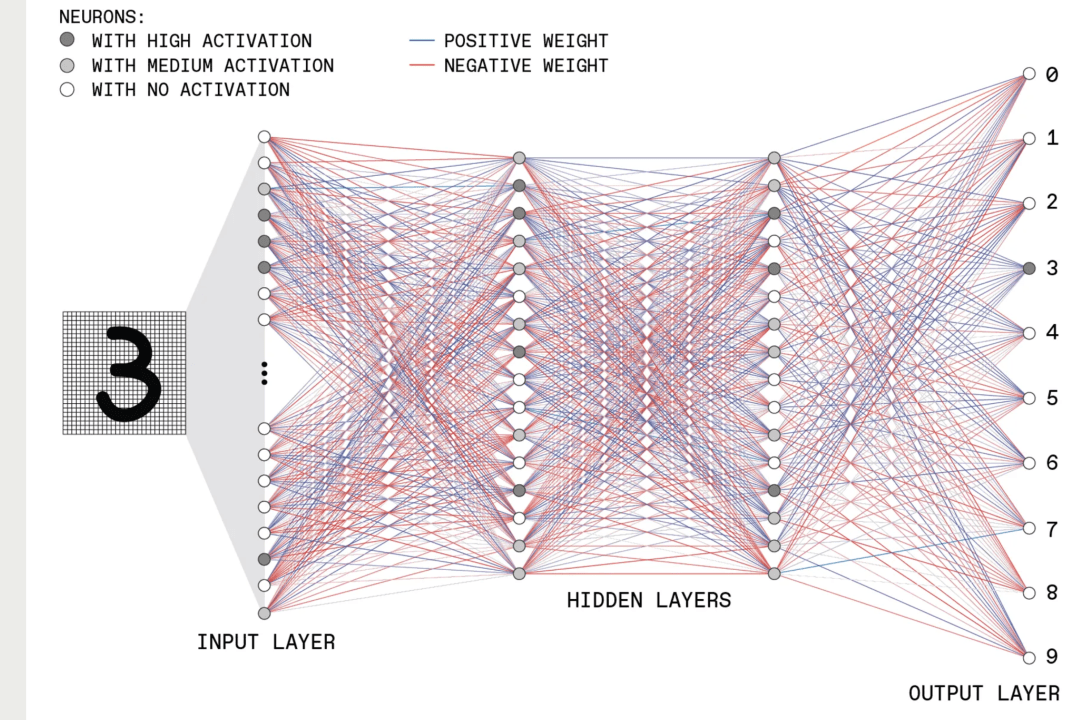
Here’s the structure of a hypothetical feed-forward deep neural network (“deep” because it contains multiple hidden layers). This example shows a network that interprets images of hand-written digits and classifies them as one of the 10 possible numerals.
The input layer contains many neurons, each of which has an activation set to the gray-scale value of one pixel in the image. These input neurons are connected to neurons in the next layer, passing on their activation levels after they have been multiplied by a certain value, called a weight. Each neuron in the second layer sums its many inputs and applies an activation function to determine its output, which is fed forward in the same manner.
TRAINING
This kind of neural network is trained by calculating the difference between the actual output and the desired output. The mathematical optimization problem here has as many dimensions as there are adjustable parameters in the network—primarily the weights of the connections between neurons, which can be positive [blue lines] or negative [red lines].
Training the network is essentially finding a minimum of this multidimensional “loss” or “cost” function. It’s done iteratively over many training runs, incrementally changing the network’s state. In practice, that entails making many small adjustments to the network’s weights based on the outputs that are computed for a random set of input examples, each time starting with the weights that control the output layer and moving backward through the network. (Only the connections to a single neuron in each layer are shown here, for simplicity.) This backpropagation process is repeated over many random sets of training examples until the loss function is minimized, and the network then provides the best results it can for any new input. DAVID SCHNEIDER
DAVID SCHNEIDER
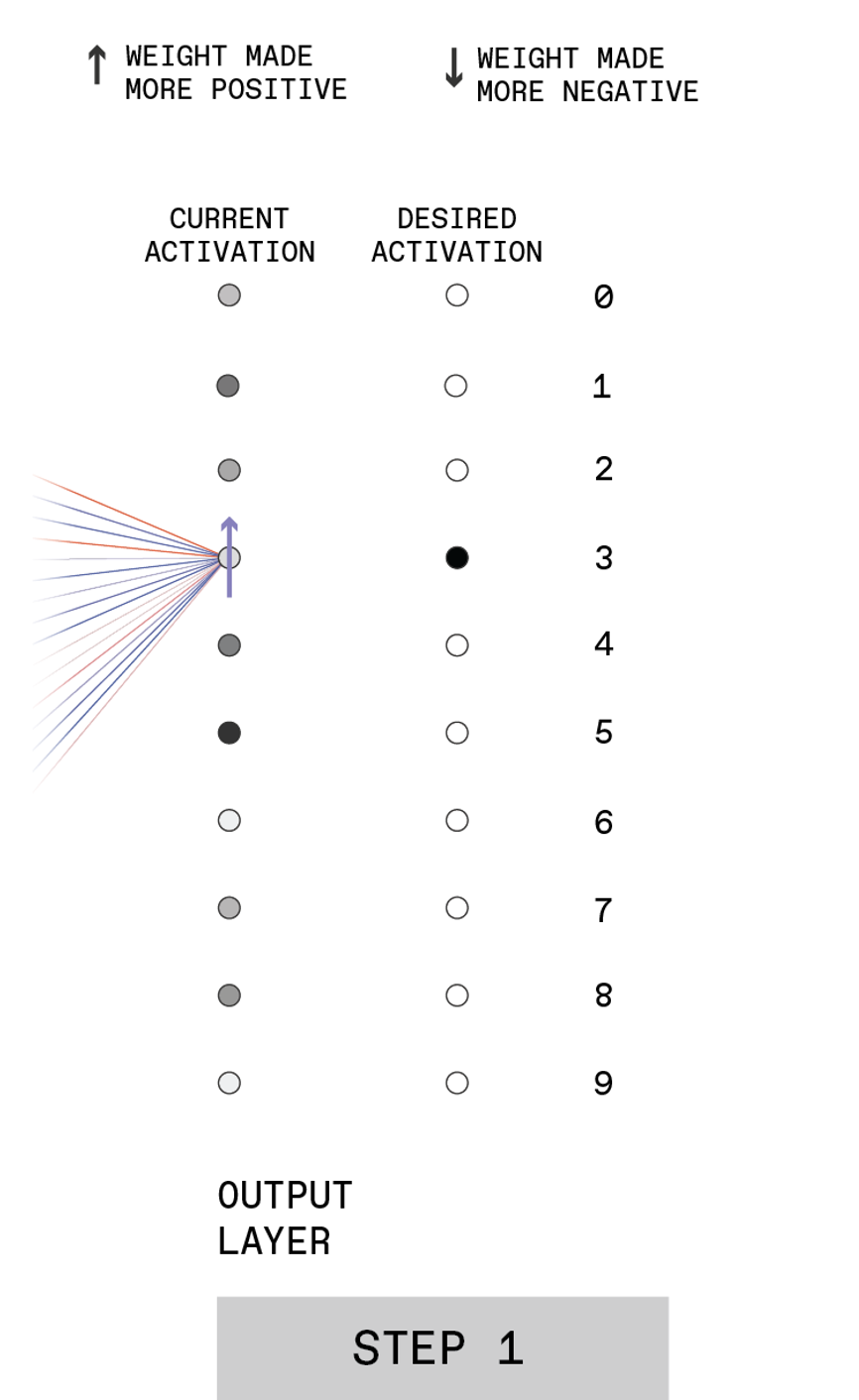
STEP 1
When presented with a handwritten “3” at the input, the output neurons of an untrained network will have random activations. The desire is for the output neuron associated with 3 to have high activation [dark shading] and other output neurons to have low activations [light shading]. So the activation of the neuron associated with 3, for example, must be increased [purple arrow].
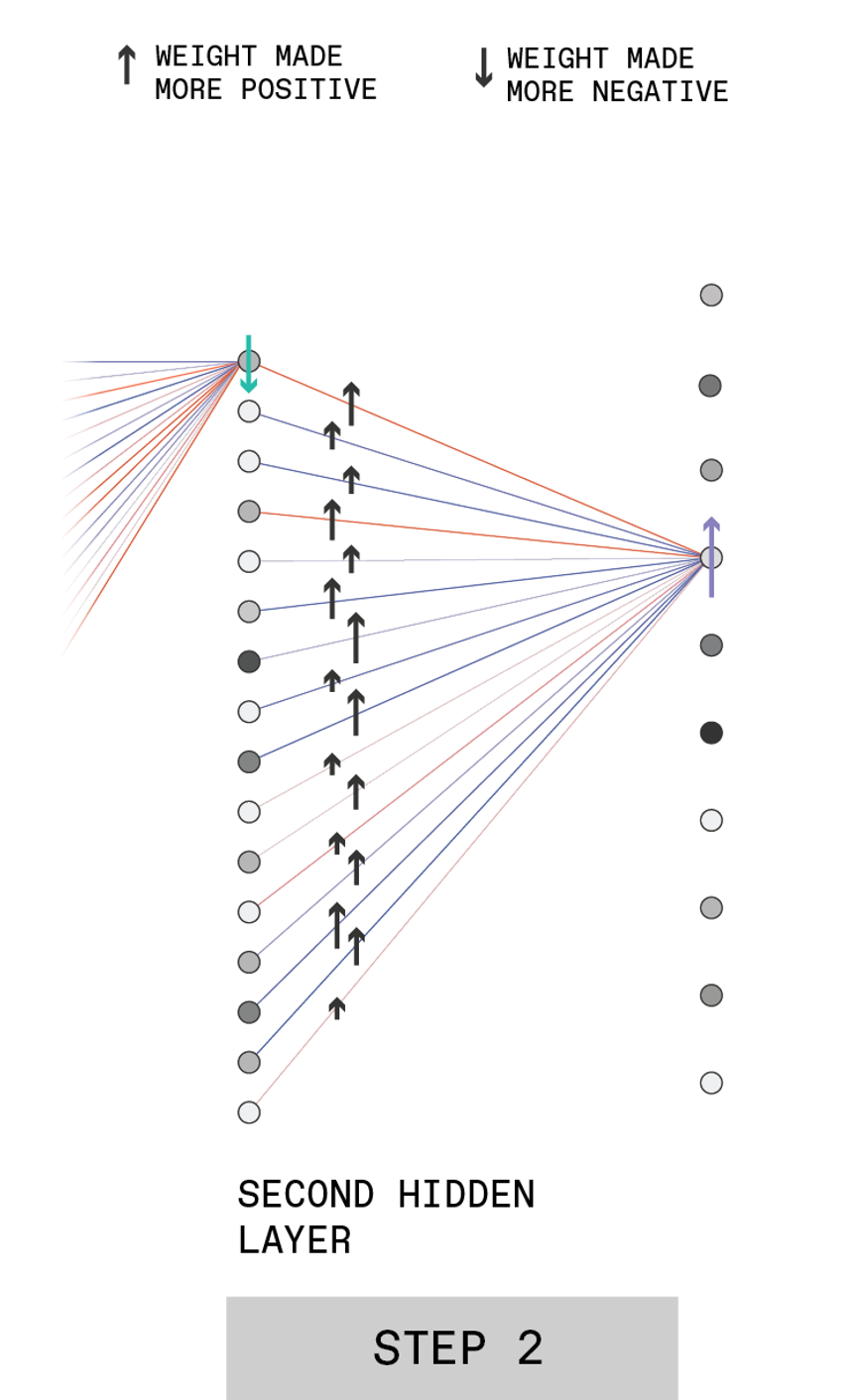
STEP 2
To do that, the weights of the connections from the neurons in the second hidden layer to the output neuron for the digit “3” should be made more positive [black arrows], with the size of the change being proportional to the activation of the connected
hidden neuron.

STEP 3
A similar process is then performed for the neurons in the second hidden layer. For example, to make the network more accurate, the top neuron in this layer may need to have its activation reduced [green arrow]. The network can be pushed in that direction by adjusting the weights of its connections with the first hidden layer [black arrows].
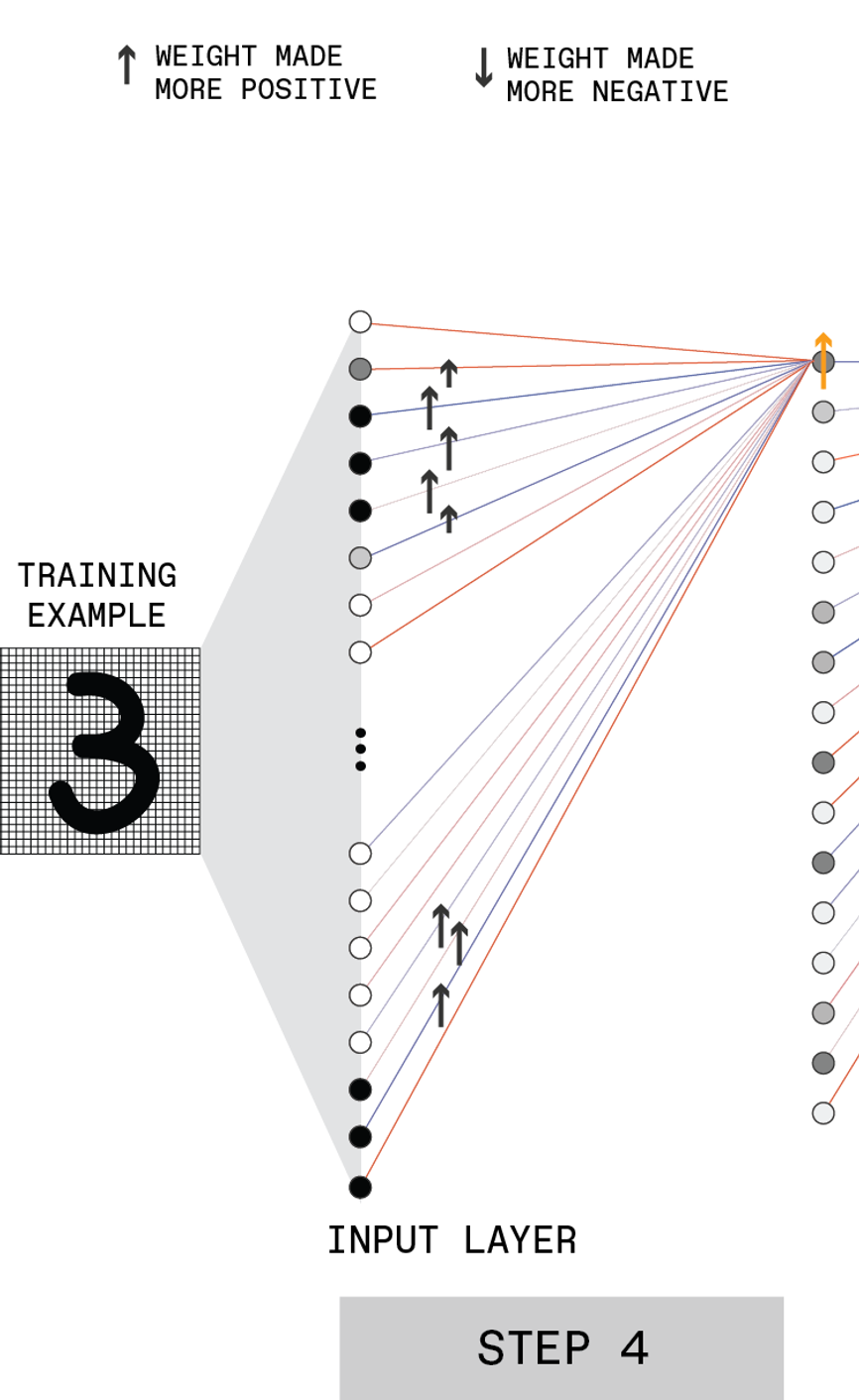
STEP 4
The process is then repeated for the first hidden layer. For example, the first neuron in this layer may need to have its activation increased [orange arrow].
